Dr. Trevor Ablett
Doctoral Candidate (2025)Department: Alumni
As we get closer to applying robotics to unstructured environments filled with humans, such as homes, roads, and hospitals, our traditional sense-plan-act approach has started to hit barriers. Reinforcement and imitation learning offer an appealing option for circumventing these limitations, in the same way that machine learning has completely revolutionized our capabilities in computer vision and language processing. Unfortunately, these techniques continue to be challenging to apply directly to robotics due to their high data requirements and inherent lack of focus on safety and robustness.
During Trevor’s PhD studies, he completed a year-long internship at Samsung AI Center in Montreal as an Applied Reinforcement Learning Researcher. He previously completed both a B. Eng in Mechatronics Engineering and a B. A. in Psychology at McMaster University in Hamilton, Ontario, Canada.
Force-Matched Imitation Learning with a See-Through Visuotactile Sensor
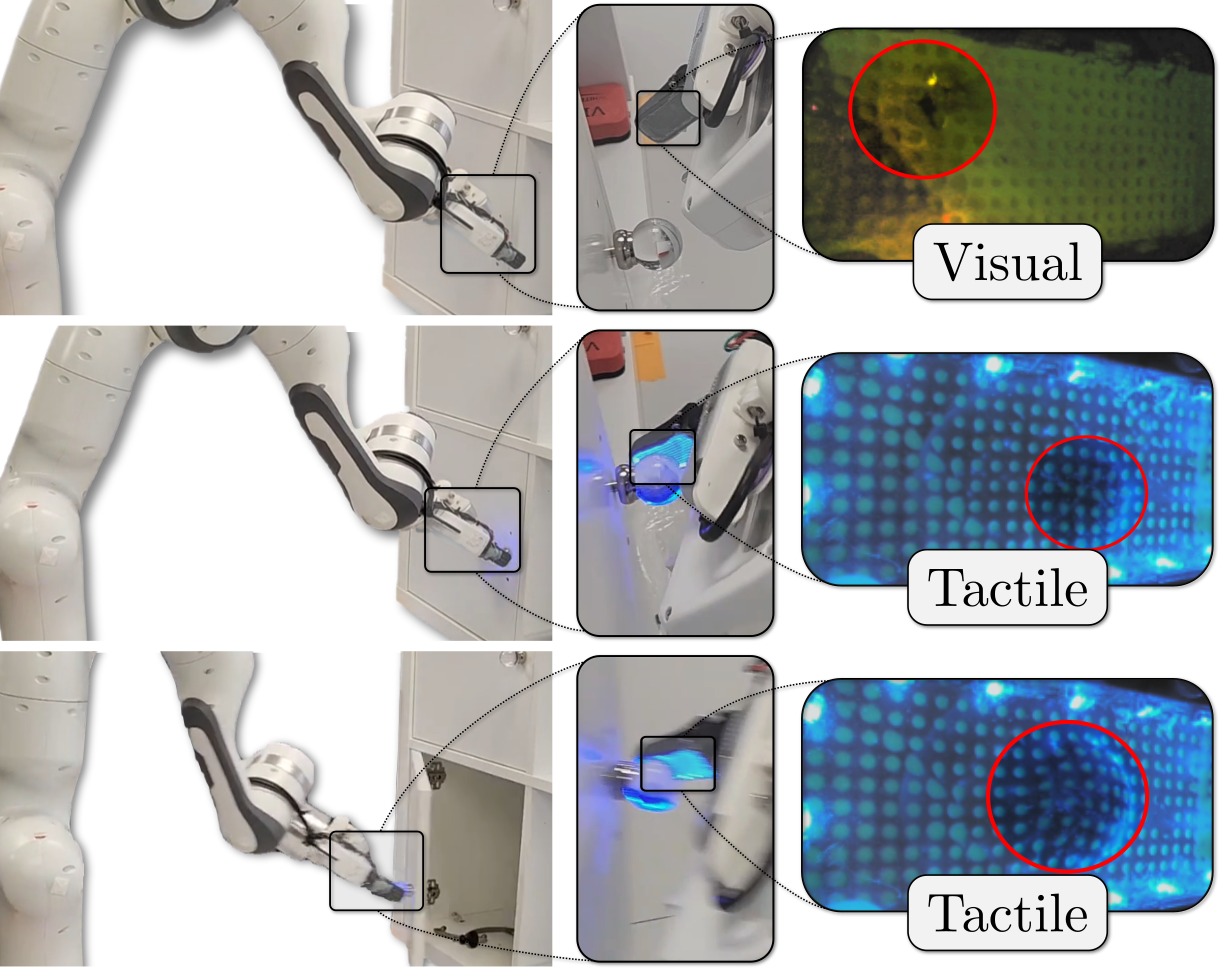
We learn to complete contact-rich cabinet opening and closing tasks with a two-mode, see-through sensor.
Trevor Ablett, Oliver Limoyo, Adam Sigal, Affan Jilani, Jonathan Kelly, Kaleem Siddiqi, Francois Hogan, Gregory Dudek
IEEE Transactions on Robotics (T-RO): Special Section on Tactile Robotics
Learning from Guided Play
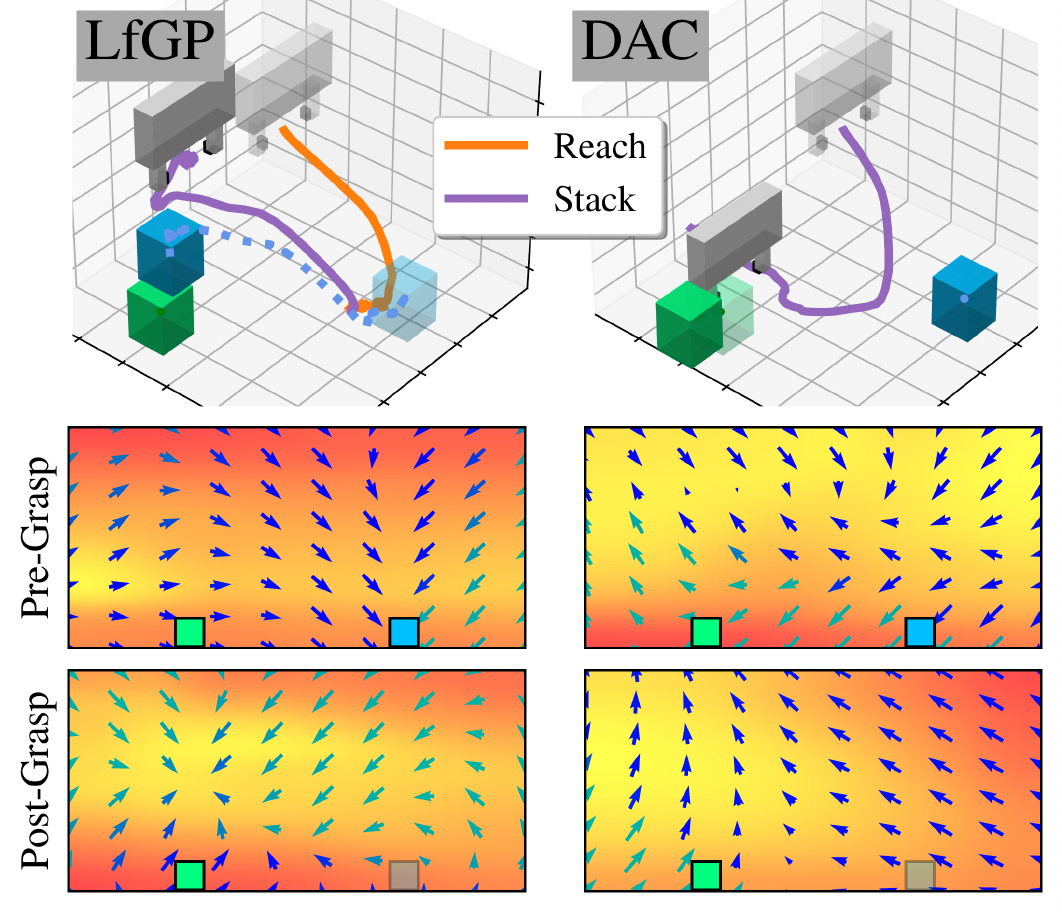
We resolve a deceptive reward problem in inverse reinforcement learning through the use of auxiliary tasks.
Trevor Ablett, Bryan Chan, Jayce Haoran Wang, Jonathan Kelly
IEEE International Conference on Robotics and Automation (ICRA’25)
Trevor Ablett, Bryan Chan, Jonathan Kelly
Robotics and Automation Letters (RA-L) and IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS’23)
Multiview Manipulation from Demonstrations

We show how imitation learning with teleoperated demonstrations can be applied to a mobile manipulator through initial pose randomization.
Trevor Ablett, Daniel (Yifan) Zhai, Jonathan Kelly
IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS’21)
Failure Identification in Intervention-based Learning
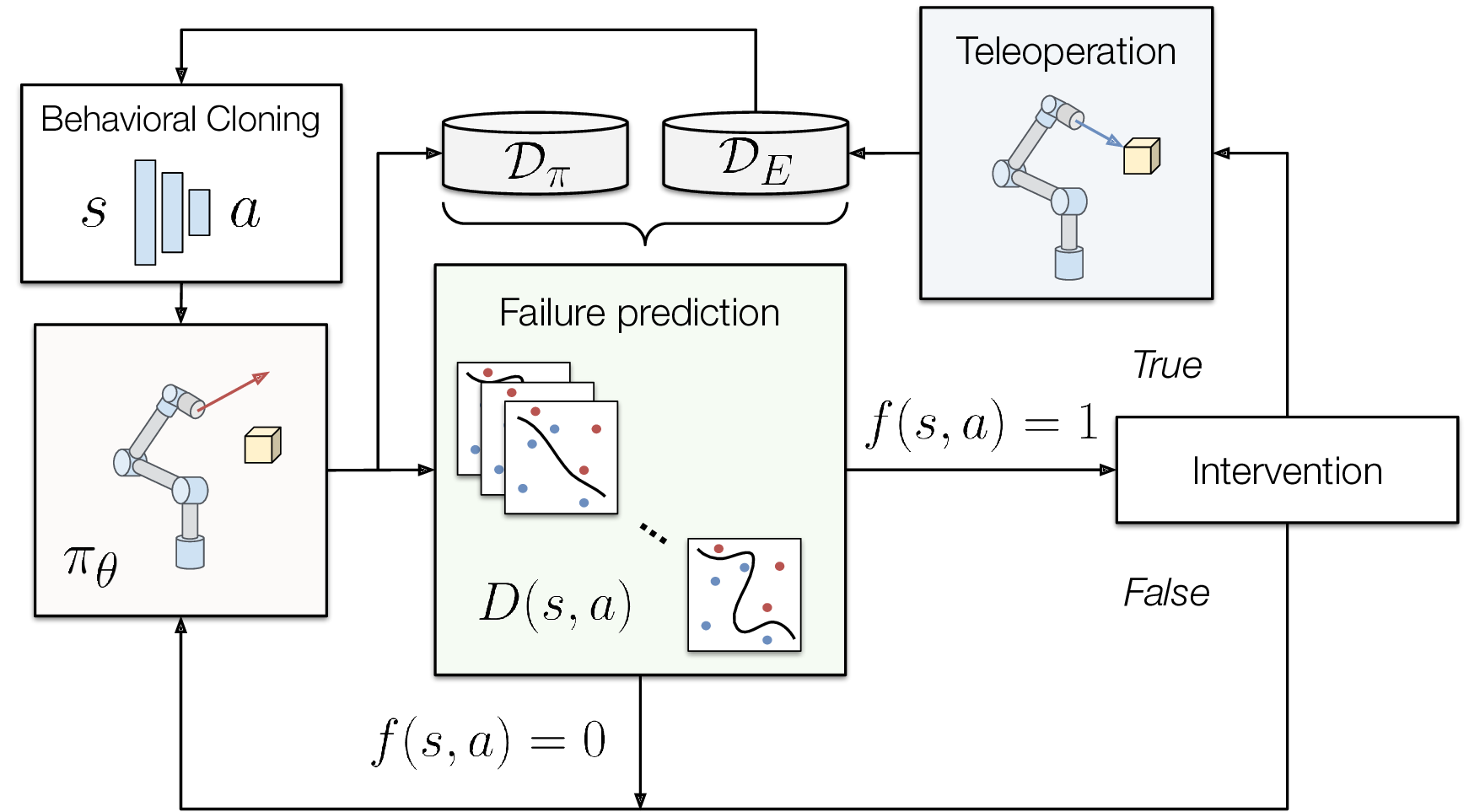
We show how identifying failures in intervention-based learning can improve learning efficiency for manipulation tasks.
Trevor Ablett, Daniel (Yifan) Zhai, Jonathan Kelly
Technical Report on arXiv (2020)
Self-Calibration of Mobile Manipulator Kinematic and Sensor Extrinsic Parameters Through Contact-Based Interaction
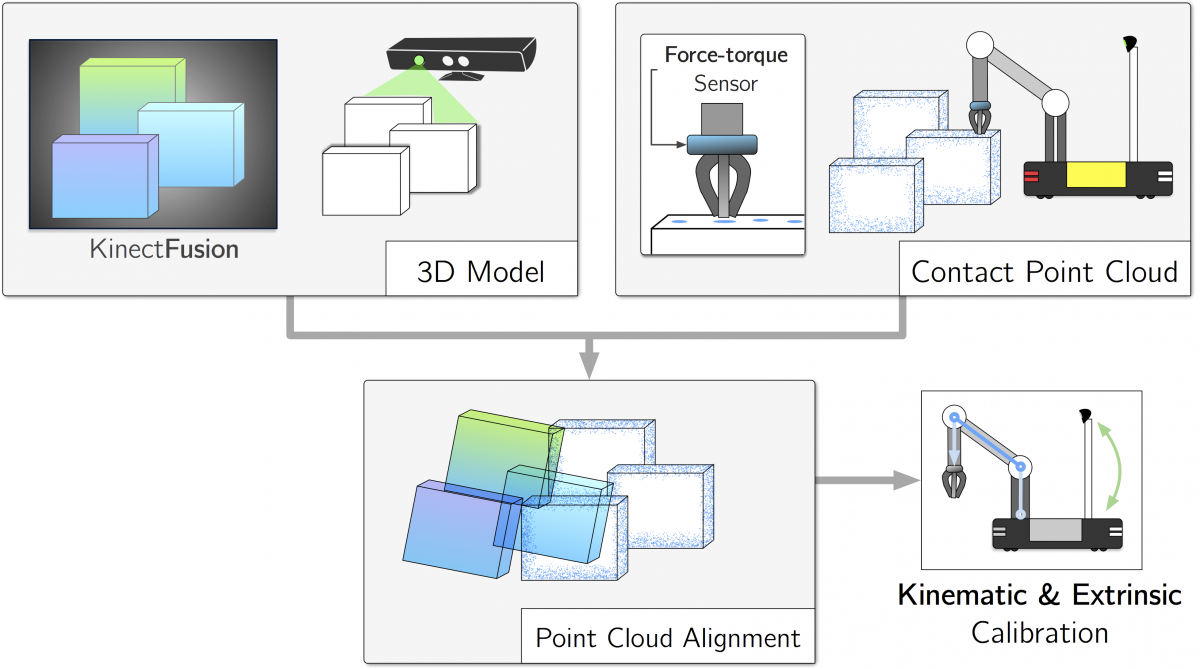
Our contact-based self-calibration procedure exclusively uses its immediate environment and on-board sensors.
Oliver Limoyo, Trevor Ablett, Filip Marić, Luke Volpatti and Jonathan Kelly
International Conference on Robotics and Automation (ICRA’18).